Nepenthe: ML Research Talent in IT Consultancies
View project on GitHubEveryone agrees the AI safety field needs more technical talent. But where do you actually find it?
While working on the Peregrine Report — where 48 experts proposed 208 interventions to reduce AI risk — talent bottlenecks kept surfacing as a core constraint. Many promising projects were considered blocked not by ideas or funding, but by a shortage of competent ML engineers and researchers who could execute difficult alignment and evaluation work.
That raised a practical question: could you simply buy this talent from existing IT consultancies? These firms collectively employ millions of people and are investing billions in AI capabilities. If even a fraction of that workforce has the technical depth needed for AI assurance work, that changes the math on how fast the field can scale.
To find out, we turned this into a rigorous study.
What we did
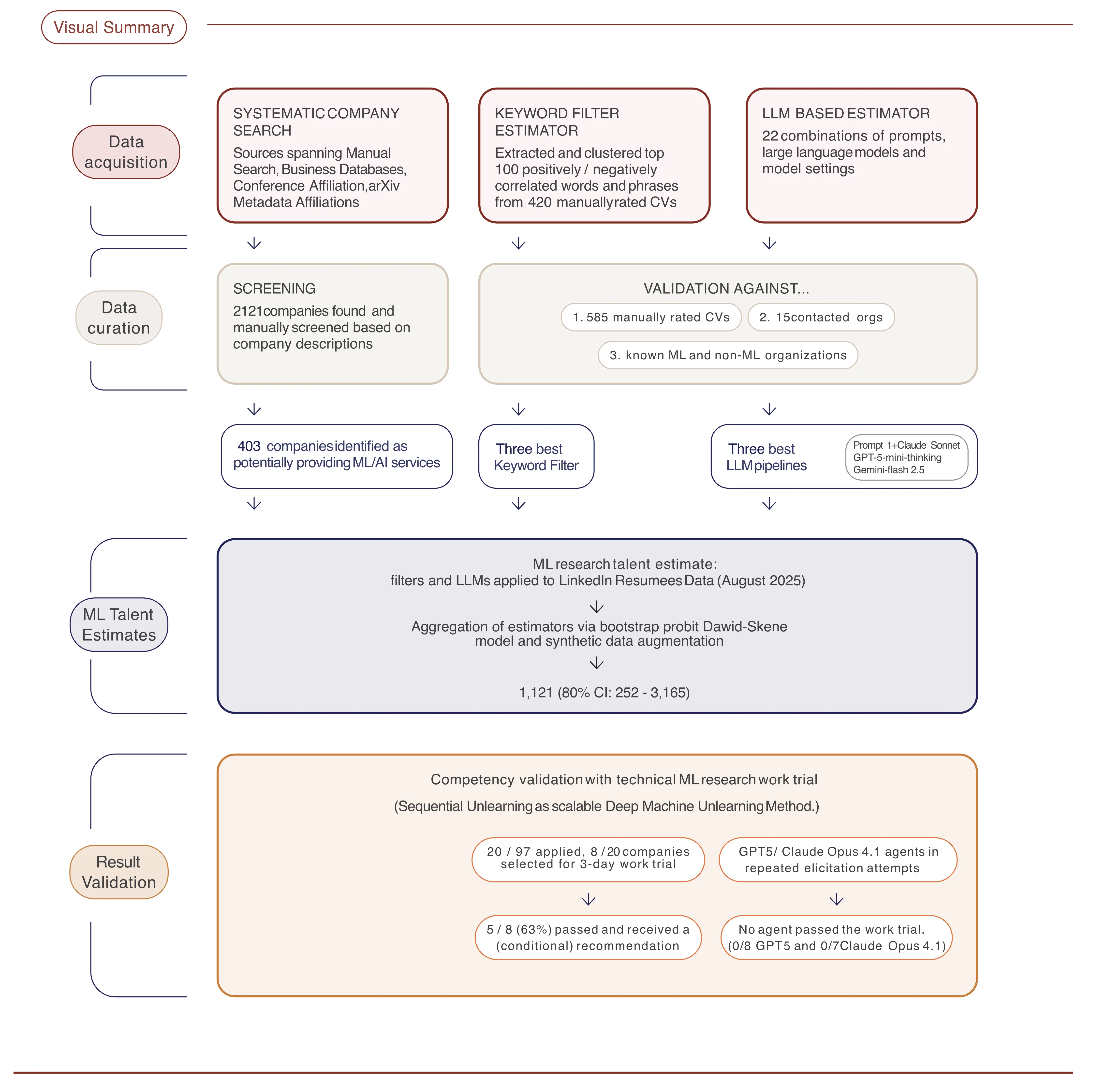
We conducted the first systematic assessment of technical ML research talent inside IT consultancies worldwide. The project had three parts:
-
Systematic company search — We screened 2,121 organizations across web searches, business databases, arXiv affiliations, and major ML conference proceedings (ICLR, ICML, NeurIPS). After filtering, 403 companies remained that credibly offer ML consulting services.
-
Talent estimation — We assessed 3.27 million employees via LinkedIn data, using validated keyword filters and LLM-based resume evaluators (calibrated against 585 manually rated CVs). Predictions were aggregated via a bootstrap probit model with size-stratified priors.
-
Work trials — We ran 3-day technical work trials where consultancies implemented a Sequential Unlearning method for deep machine unlearning. We also benchmarked GPT-5 and Claude Opus 4.1 agents on the same task.
Key findings
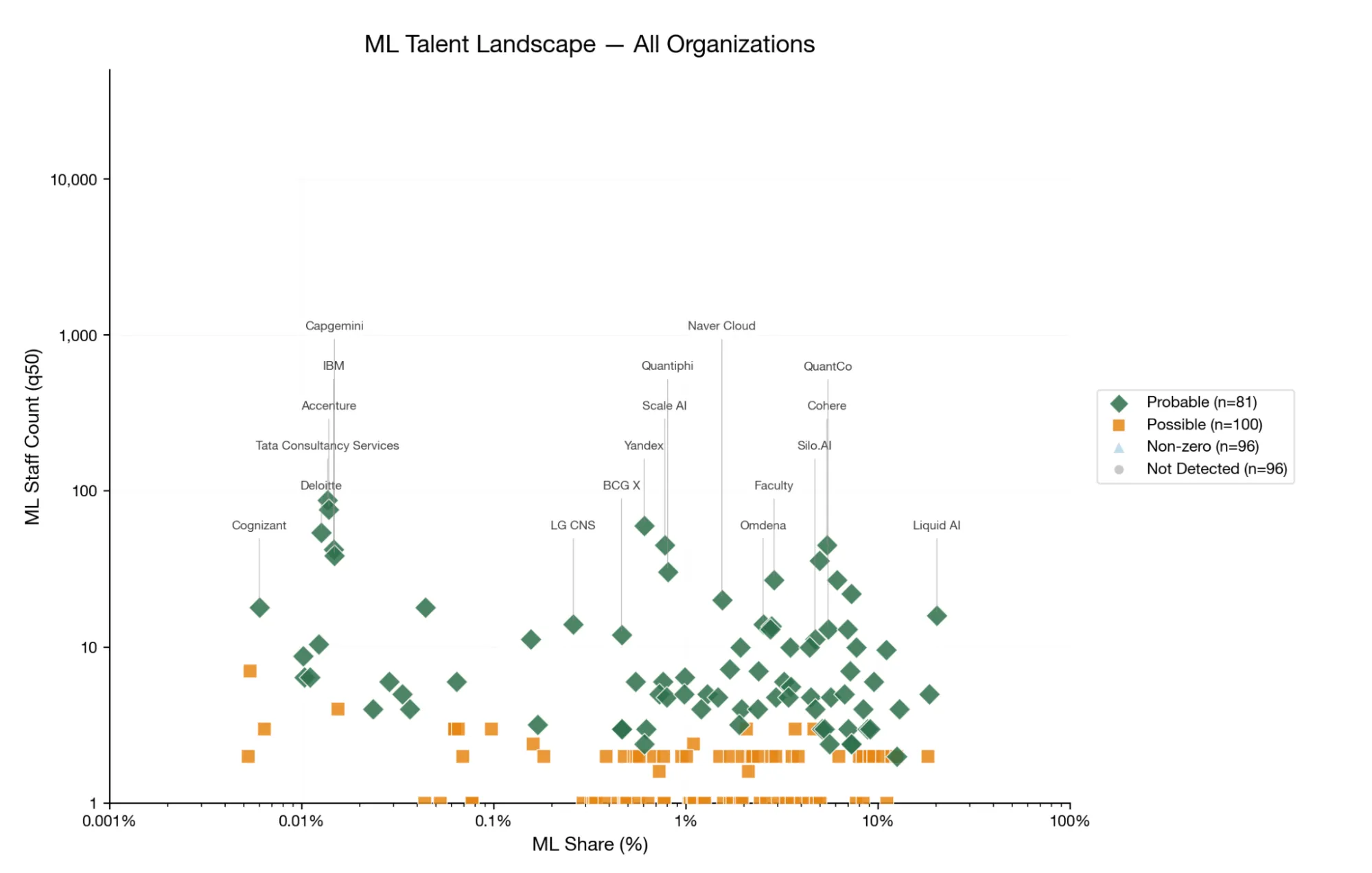
- ~1,100 highly technical ML practitioners (80% CI: 252–3,165) sit inside these 403 consultancies — largely invisible to the AI safety ecosystem.
- Talent is concentrated: 81 firms showed confident ML presence, accounting for ~80% of all identified talent.
- 5 of 8 consultancies that completed the work trial received a recommendation or conditional recommendation — with three scoring above 90%.
- No AI agent passed the work trial. Both GPT-5 and Claude Opus 4.1 scored 30–40% despite repeated expert elicitation, receiving no recommendation.
Why this matters
There is a real, validated pool of ML research talent in IT consultancies that could be activated for AI assurance work. From our experience working with these firms, there is also genuine excitement on the consultancy side for challenging research work.
This isn’t a theoretical argument. We found the people, tested their capabilities against a concrete technical benchmark, and compared them to state-of-the-art AI agents. The consultancies won convincingly.
For funders and program managers looking to scale technical AI safety capacity, this is an accelerated path worth considering.
How the estimation pipeline works
Estimating true ML research competence from LinkedIn resumes is noisy. We designed a multi-stage pipeline to make it robust:
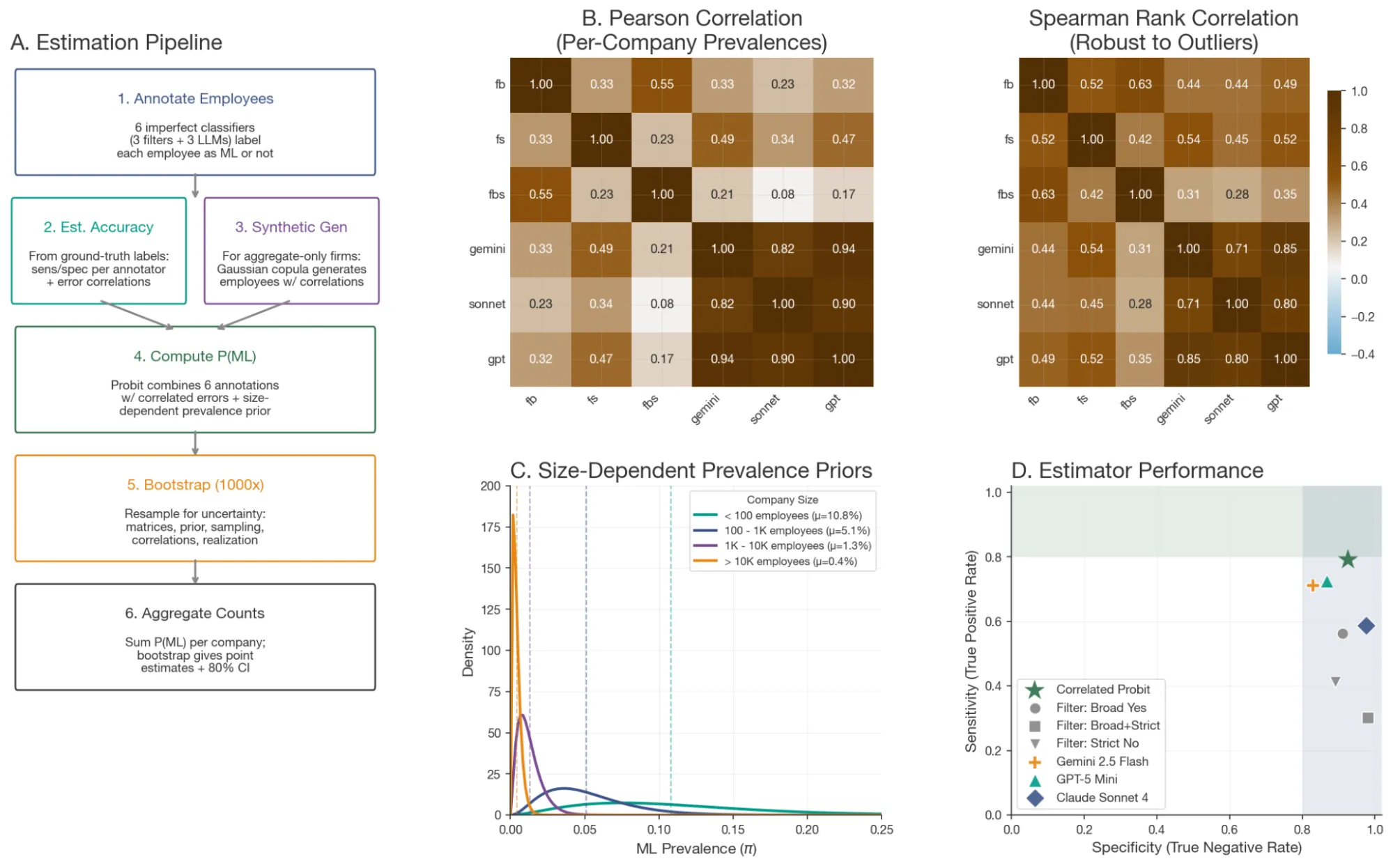
We first hand-labeled 585 CVs against a strict definition of technical ML talent — people who can train models from scratch, implement architectures end-to-end, and debug training runs. From these, we extracted discriminative keyword filters and developed LLM-based evaluation prompts tested across 22 combinations of models and settings (GPT-5, Gemini 2.5, Claude Sonnet 4).
The best-performing estimators were combined via a bootstrap probit model with size-stratified priors — accounting for the fact that a 50-person ML boutique and a 100,000-person conglomerate have very different base rates of technical talent. For companies where LLM estimates weren’t available, we used synthetic data imputation. The final estimator achieved a sensitivity of 0.79 and specificity of 0.93 against our validation datasets.
As an additional validation step, we applied the full pipeline to organizations with known profiles. It correctly identified high technical ML talent counts at established AI labs (e.g., OpenAI, Mistral AI, HuggingFace) and returned low-to-zero counts for non-AI companies (e.g., Patagonia, Crocs, The British Museum) — confirming that the priors and estimators generalize beyond our consultancy sample.
For the full methodological details — including the keyword extraction process, prompt design, bootstrap procedure, and all validation results — see the preprint (coming soon) and the GitHub repository.
Collaborators
Red Bermejo (investigation, data curation), Florian Aldehoff-Zeidler (software, formal analysis), Niccolo Zanichelli (conceptualization, investigation), Oliver Evans (methodology, software, formal analysis), Gavin Leech (methodology, conceptualization), Samuel Hargestam (conceptualization, supervision).
Funded by Coefficient Giving. Work trial benchmarking supported by Lucas Sato (METR).