Nepenthe:IT咨询公司中的ML研究人才
在GitHub上查看项目每个人都同意AI安全领域需要更多技术人才。但你实际上在哪里找到他们?
在撰写Peregrine报告的过程中——48位专家提出了208项减少AI风险的干预措施——人才瓶颈反复浮现为核心约束。许多有前景的项目被认为受阻的原因不是缺少想法或资金,而是缺乏能够执行困难的对齐和评估工作的称职ML工程师和研究人员。
这引出了一个实际问题:能否直接从现有的IT咨询公司购买这些人才?这些公司共雇用数百万人,并在AI能力方面投资数十亿。如果即使其中一小部分劳动力具有AI安全工作所需的技术深度,这将改变该领域扩展速度的计算。
为了找到答案,我们将其转化为一项严格的研究。
我们做了什么
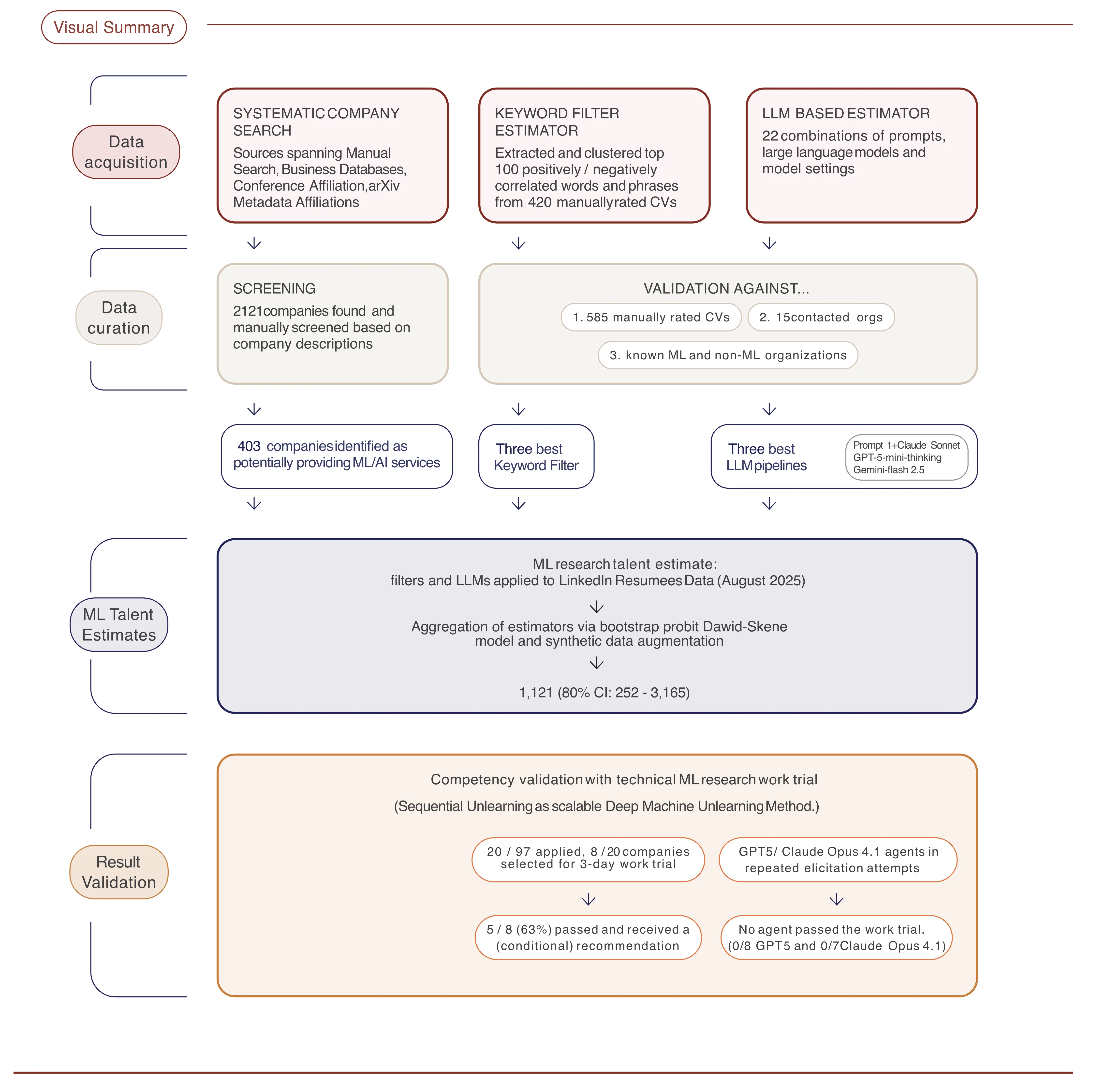
我们对全球IT咨询公司内部的技术ML研究人才进行了首次系统评估。该项目分为三个部分:
-
系统性公司搜索 — 我们通过网络搜索、商业数据库、arXiv从属关系和主要ML会议论文集(ICLR、ICML、NeurIPS)筛选了2,121个组织。过滤后,剩下403家可信地提供ML咨询服务的公司。
-
人才估算 — 我们通过LinkedIn数据评估了327万名员工,使用经验证的关键词过滤器和基于LLM的简历评估器(根据585份人工评级的简历进行校准)。预测通过带有规模分层先验的自举probit模型进行汇总。
-
工作试用 — 我们进行了为期3天的技术工作试用,咨询公司实施了用于深度机器遗忘的Sequential Unlearning方法。我们还在同一任务上对GPT-5和Claude Opus 4.1代理进行了基准测试。
关键发现
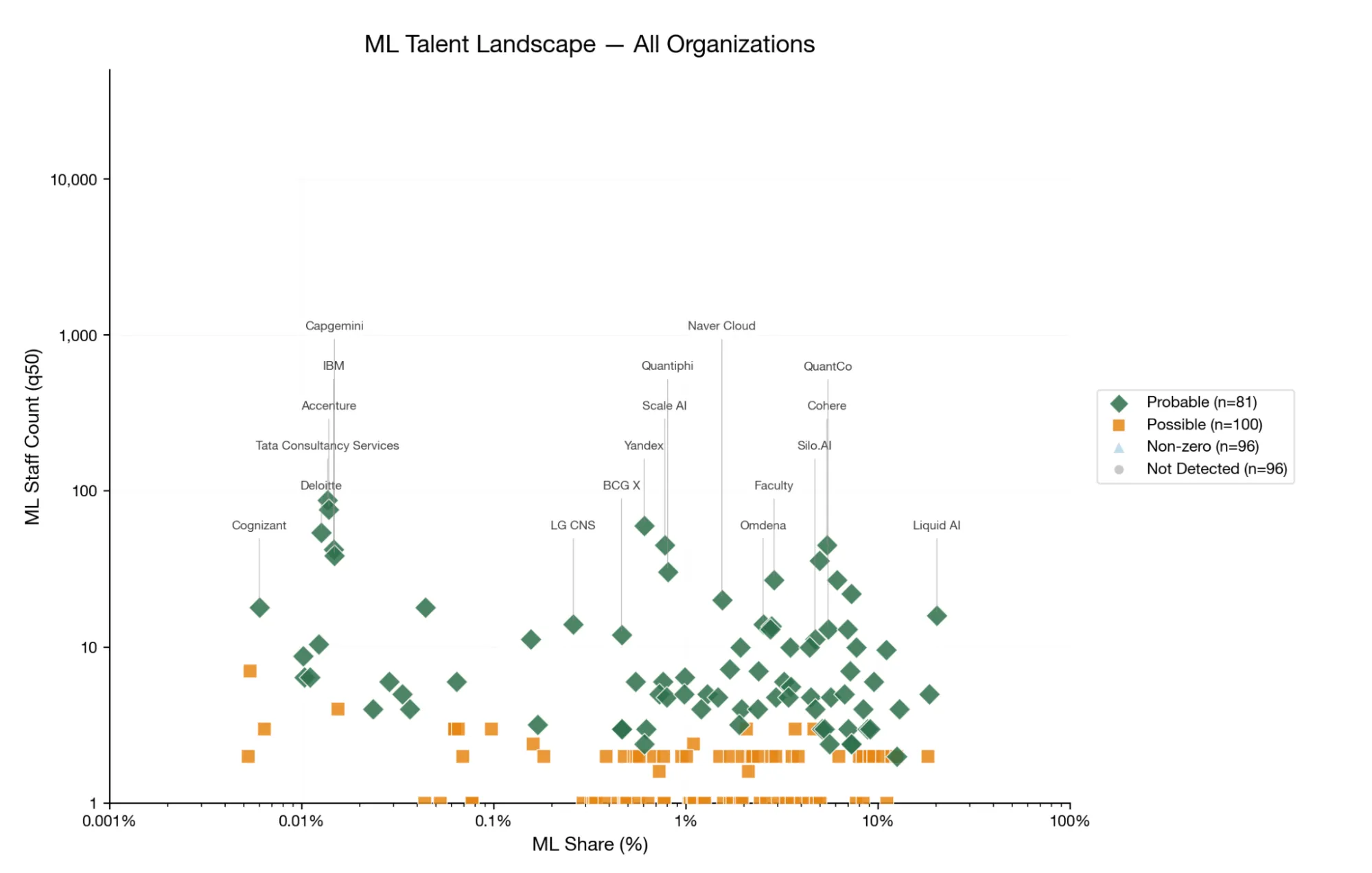
- 约1,100名高技术ML从业者(80%置信区间:252–3,165)分布在这403家咨询公司中——对AI安全生态系统来说基本上是不可见的。
- 人才是集中的:81家公司显示出确定的ML存在,占所有已识别人才的约80%。
- 完成工作试用的8家咨询公司中有5家获得了推荐或有条件推荐——其中三家得分超过90%。
- 没有AI代理通过工作试用。 GPT-5和Claude Opus 4.1尽管经过反复的专家调优,得分仅为30-40%,未获得推荐。
为什么这很重要
IT咨询公司中存在一个真实的、经过验证的ML研究人才库,可以为AI安全工作所激活。根据我们与这些公司合作的经验,咨询公司方面对具有挑战性的研究工作也有真正的热情。
这不是一个理论论点。我们找到了这些人,根据具体的技术基准测试了他们的能力,并将他们与最先进的AI代理进行了比较。咨询公司令人信服地获胜。
对于希望扩大技术AI安全能力的资助者和项目经理来说,这是一条值得考虑的加速路径。
估算流程如何运作
从LinkedIn简历估算真正的ML研究能力是有噪声的。我们设计了一个多阶段流程使其具有鲁棒性:
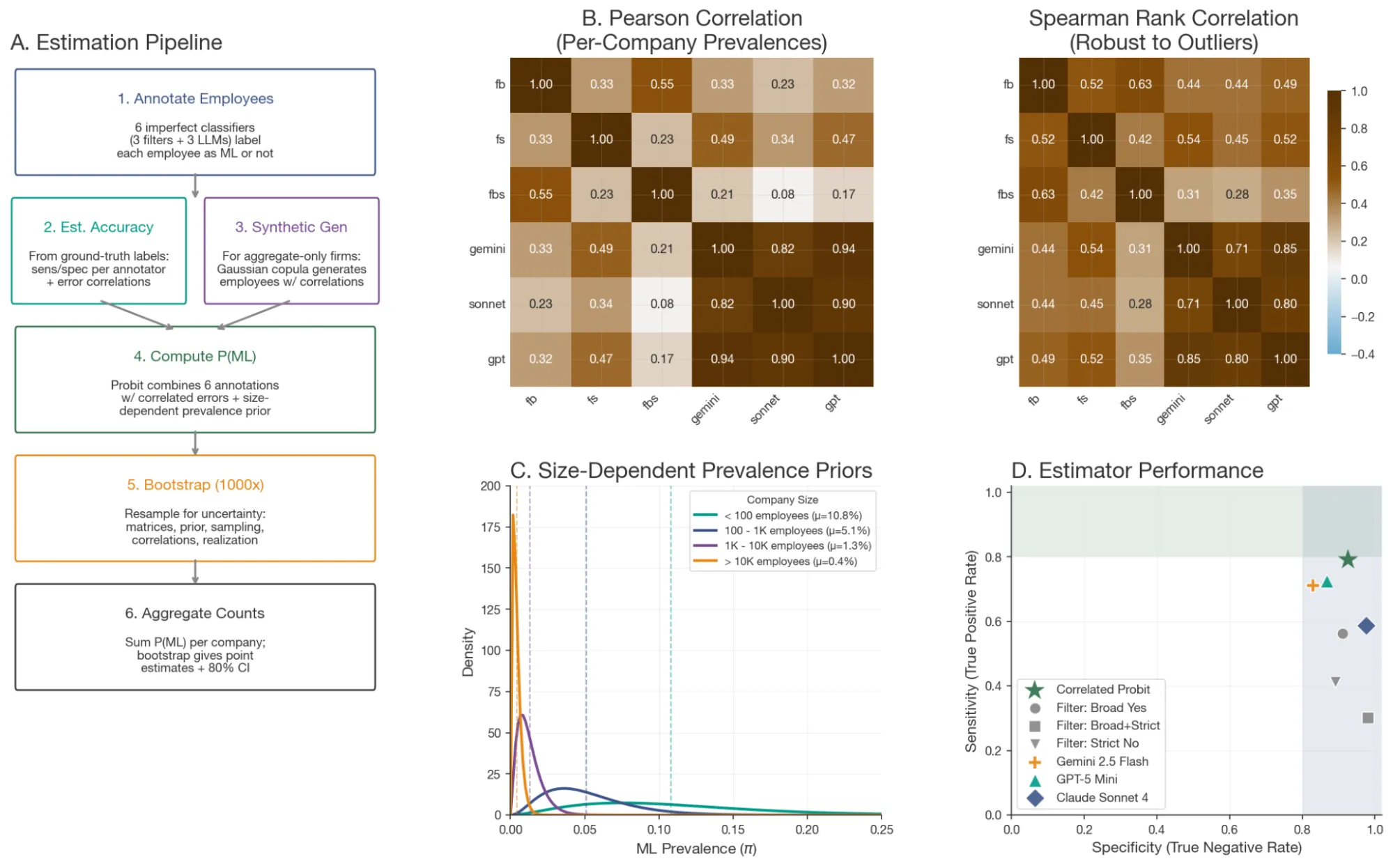
我们首先根据技术ML人才的严格定义手工标注了585份简历——能够从零开始训练模型、端到端实现架构并调试训练运行的人。从中我们提取了判别性关键词过滤器,并开发了基于LLM的评估提示,在22种模型和设置组合(GPT-5、Gemini 2.5、Claude Sonnet 4)中进行了测试。
表现最佳的评估器通过带有规模分层先验的自举probit模型进行组合——考虑到50人的ML精品店和10万人的企业集团具有非常不同的技术人才基础率。对于没有LLM估算的公司,我们使用了合成数据插补。最终评估器在我们的验证数据集上达到了0.79的敏感性和0.93的特异性。
作为额外的验证步骤,我们将完整流程应用于具有已知特征的组织。它正确识别了成熟AI实验室(如OpenAI、Mistral AI、HuggingFace)的高技术ML人才数量,并对非AI公司(如Patagonia、Crocs、大英博物馆)返回了低至零的数值——确认先验和评估器能够泛化到我们的咨询样本之外。
有关完整的方法论细节——包括关键词提取过程、提示设计、自举程序和所有验证结果——请参阅预印本(即将发布)和GitHub仓库。
合作者
Red Bermejo(调查、数据管理)、Florian Aldehoff-Zeidler(软件、形式分析)、Niccolo Zanichelli(概念化、调查)、Oliver Evans(方法论、软件、形式分析)、Gavin Leech(方法论、概念化)、Samuel Hargestam(概念化、监督)。
由Coefficient Giving资助。工作试用基准测试由Lucas Sato(METR)支持。