Nepenthe: ML-Forschungstalent in IT-Beratungsunternehmen
Projekt auf GitHub ansehenAlle sind sich einig, dass der Bereich KI-Sicherheit mehr technisches Talent benötigt. Aber wo findet man es tatsächlich?
Bei der Arbeit am Peregrine Report – in dem 48 Experten 208 Interventionen zur Reduzierung von KI-Risiken vorschlugen – tauchten Talentengpässe immer wieder als zentrale Einschränkung auf. Viele vielversprechende Projekte galten nicht als blockiert durch fehlende Ideen oder Finanzierung, sondern durch einen Mangel an kompetenten ML-Ingenieuren und Forschern, die anspruchsvolle Alignment- und Evaluierungsarbeit durchführen konnten.
Das warf eine praktische Frage auf: Könnte man dieses Talent einfach von bestehenden IT-Beratungsunternehmen einkaufen? Diese Firmen beschäftigen zusammen Millionen von Menschen und investieren Milliarden in KI-Fähigkeiten. Wenn auch nur ein Bruchteil dieser Belegschaft die nötige technische Tiefe für KI-Sicherheitsarbeit mitbringt, verändert das die Rechnung, wie schnell das Feld skalieren kann.
Um das herauszufinden, haben wir daraus eine rigorose Studie gemacht.
Was wir gemacht haben
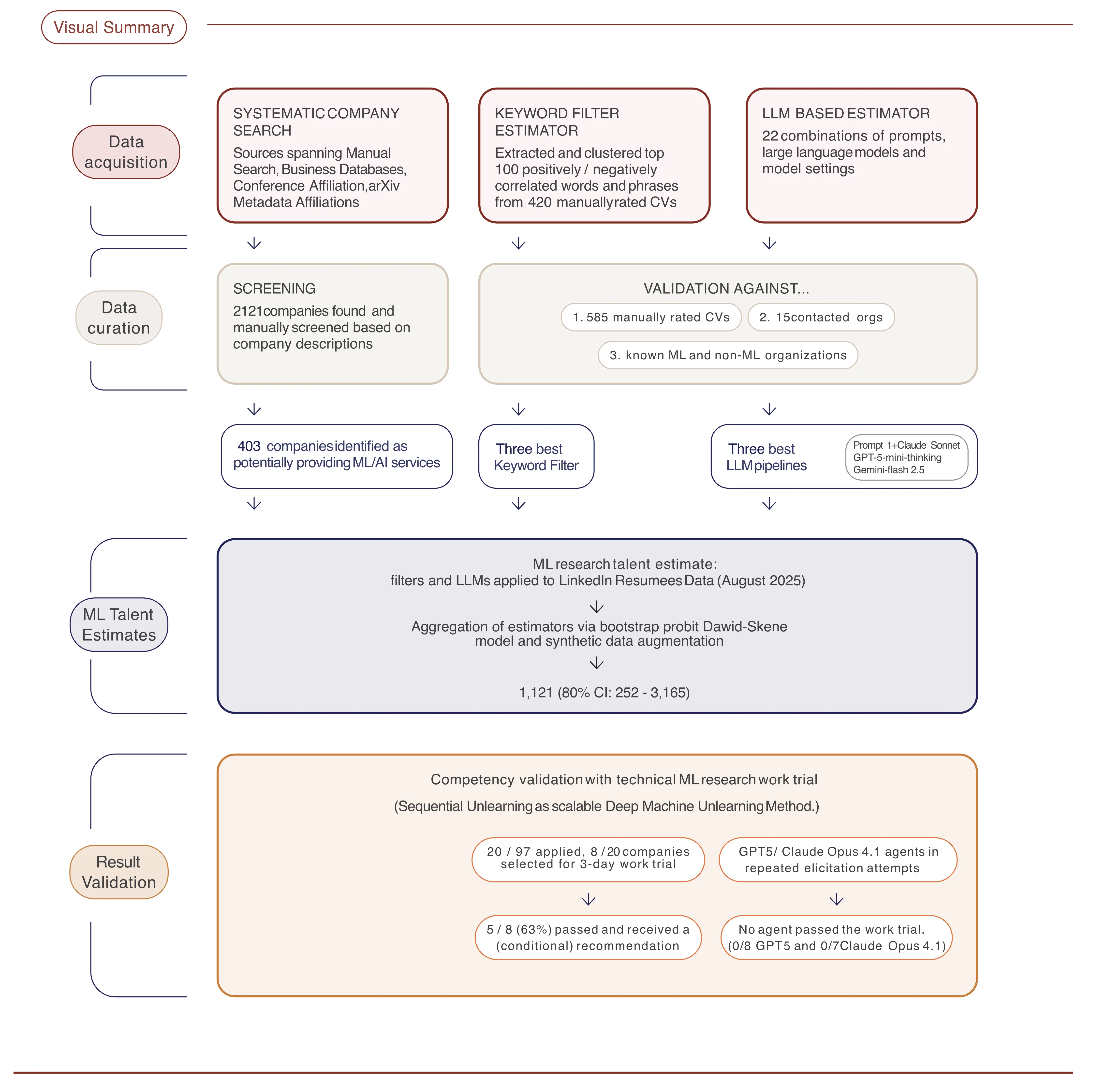
Wir haben die erste systematische Bewertung des technischen ML-Forschungstalents in IT-Beratungsunternehmen weltweit durchgeführt. Das Projekt hatte drei Teile:
-
Systematische Unternehmenssuche — Wir haben 2.121 Organisationen über Websuchen, Geschäftsdatenbanken, arXiv-Affiliationen und führende ML-Konferenzberichte (ICLR, ICML, NeurIPS) durchsucht. Nach der Filterung verblieben 403 Unternehmen, die glaubwürdig ML-Beratungsdienste anbieten.
-
Talentschätzung — Wir haben 3,27 Millionen Mitarbeiter über LinkedIn-Daten bewertet, unter Verwendung validierter Keyword-Filter und LLM-basierter Lebenslauf-Evaluatoren (kalibriert anhand von 585 manuell bewerteten Lebensläufen). Die Vorhersagen wurden über ein Bootstrap-Probit-Modell mit größenabhängigen Priors aggregiert.
-
Arbeitsproben — Wir haben 3-tägige technische Arbeitsproben durchgeführt, bei denen Beratungsunternehmen eine Sequential-Unlearning-Methode für tiefes maschinelles Verlernen implementierten. Wir haben auch GPT-5 und Claude Opus 4.1 Agenten an derselben Aufgabe getestet.
Zentrale Ergebnisse
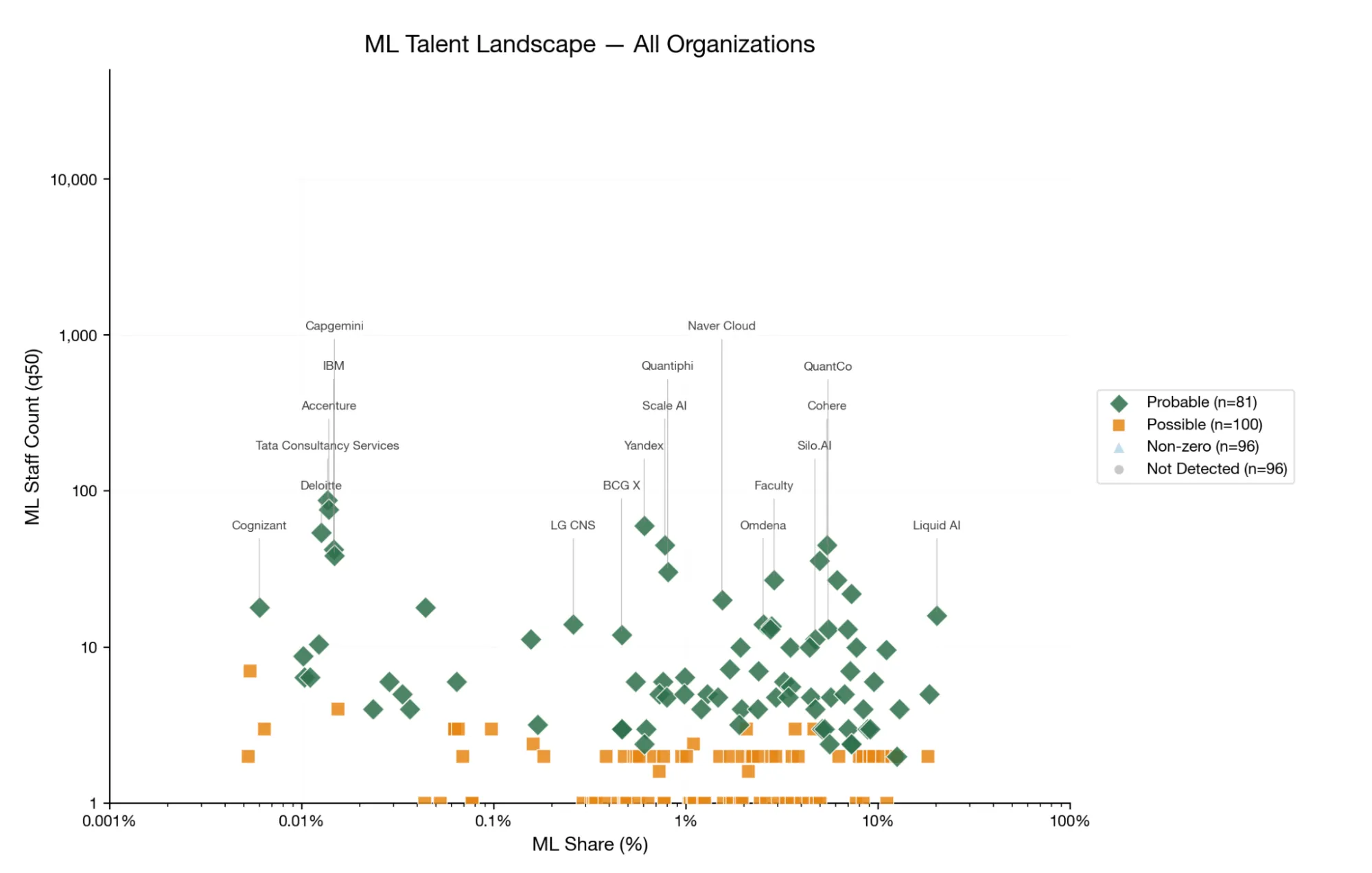
- ~1.100 hochtechnische ML-Praktiker (80%-KI: 252–3.165) sitzen in diesen 403 Beratungsunternehmen – weitgehend unsichtbar für das KI-Sicherheits-Ökosystem.
- Talent ist konzentriert: 81 Firmen zeigten gesicherte ML-Präsenz und machten ~80% des gesamten identifizierten Talents aus.
- 5 von 8 Beratungsunternehmen, die die Arbeitsprobe abschlossen, erhielten eine Empfehlung oder bedingte Empfehlung – drei davon mit über 90% Bewertung.
- Kein KI-Agent bestand die Arbeitsprobe. Sowohl GPT-5 als auch Claude Opus 4.1 erzielten 30–40% trotz wiederholter Experten-Optimierung und erhielten keine Empfehlung.
Warum das wichtig ist
Es gibt einen realen, validierten Pool an ML-Forschungstalent in IT-Beratungsunternehmen, der für KI-Sicherheitsarbeit aktiviert werden könnte. Aus unserer Erfahrung in der Zusammenarbeit mit diesen Firmen gibt es auch echte Begeisterung auf der Beratungsseite für anspruchsvolle Forschungsarbeit.
Das ist kein theoretisches Argument. Wir haben die Menschen gefunden, ihre Fähigkeiten anhand eines konkreten technischen Benchmarks getestet und sie mit hochmodernen KI-Agenten verglichen. Die Beratungsunternehmen gewannen überzeugend.
Für Geldgeber und Programmmanager, die technische KI-Sicherheitskapazitäten skalieren wollen, ist dies ein beschleunigter Weg, den es zu erwägen lohnt.
Wie die Schätzungspipeline funktioniert
Die Schätzung echter ML-Forschungskompetenz aus LinkedIn-Lebensläufen ist verrauscht. Wir haben eine mehrstufige Pipeline entworfen, um sie robust zu machen:
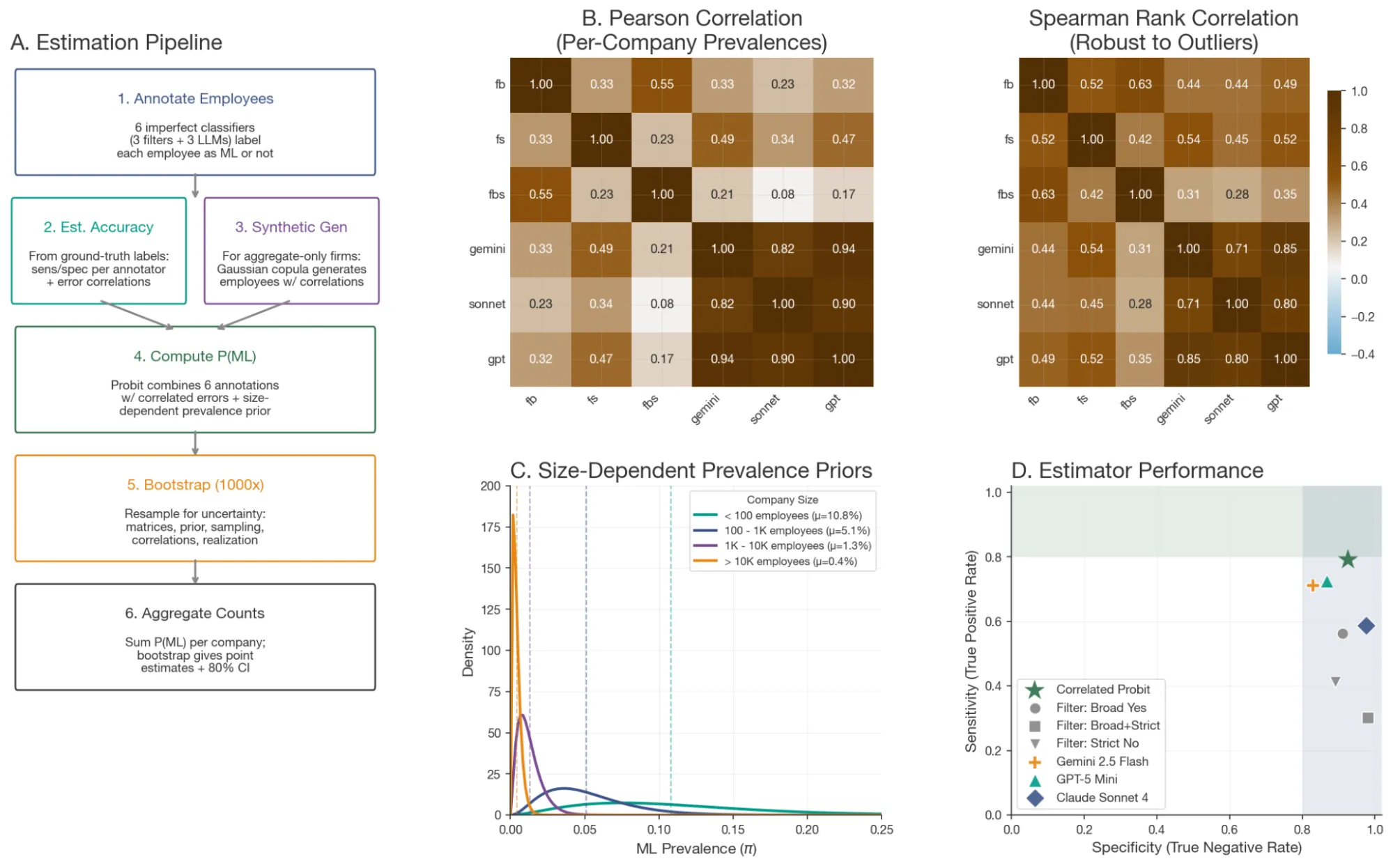
Wir haben zunächst 585 Lebensläufe nach einer strengen Definition von technischem ML-Talent handgelabelt – Personen, die Modelle von Grund auf trainieren, Architekturen End-to-End implementieren und Trainingsdurchläufe debuggen können. Daraus haben wir diskriminative Keyword-Filter extrahiert und LLM-basierte Evaluierungsprompts entwickelt, die über 22 Kombinationen von Modellen und Einstellungen (GPT-5, Gemini 2.5, Claude Sonnet 4) getestet wurden.
Die leistungsstärksten Evaluatoren wurden über ein Bootstrap-Probit-Modell mit größenabhängigen Priors kombiniert – unter Berücksichtigung der Tatsache, dass eine 50-Personen-ML-Boutique und ein 100.000-Personen-Konglomerat sehr unterschiedliche Basisraten an technischem Talent aufweisen. Für Unternehmen, bei denen keine LLM-Schätzungen verfügbar waren, verwendeten wir synthetische Datenimputation. Der finale Evaluator erreichte eine Sensitivität von 0,79 und eine Spezifität von 0,93 gegen unsere Validierungsdatensätze.
Als zusätzlichen Validierungsschritt wandten wir die gesamte Pipeline auf Organisationen mit bekannten Profilen an. Sie identifizierte korrekt hohe technische ML-Talentanzahlen bei etablierten KI-Laboren (z.B. OpenAI, Mistral AI, HuggingFace) und lieferte niedrige bis null Werte für Nicht-KI-Unternehmen (z.B. Patagonia, Crocs, The British Museum) – was bestätigt, dass die Priors und Evaluatoren über unsere Beratungsstichprobe hinaus generalisieren.
Für die vollständigen methodischen Details – einschließlich des Keyword-Extraktionsprozesses, Prompt-Designs, Bootstrap-Verfahrens und aller Validierungsergebnisse – siehe das Preprint (demnächst verfügbar) und das GitHub-Repository.
Mitarbeiter
Red Bermejo (Investigation, Datenkuration), Florian Aldehoff-Zeidler (Software, formale Analyse), Niccolo Zanichelli (Konzeptualisierung, Investigation), Oliver Evans (Methodologie, Software, formale Analyse), Gavin Leech (Methodologie, Konzeptualisierung), Samuel Hargestam (Konzeptualisierung, Supervision).
Finanziert von Coefficient Giving. Benchmarking der Arbeitsproben unterstützt von Lucas Sato (METR).